论文发表时间:2018年5月
论文地址:https://arxiv.org/abs/1805.02283
官方代码:https://github.com/seasonSH/DocFace(Tensorflow)
一、一句话总结
第一句:在人证比对场景中,「DocFace」 比通用人脸验证方案准确度更高;
第二句:将迁移学习应用到人脸验证,且为人证比对问题设计了新的 Loss 函数;迁移学习专题
二、Q&A
人工比对,耗时耗力且容易出错;之前的人证比对方案也都是 2011 年以前了;因此我们使用近年发展迅速的 DNN 来处理人证比对问题;
1.证件照图像质量低;what 证件照与自拍照有年龄差距;人脸识别也有面临这个问题吧
2.人证比对数据集缺乏;
使用迁移学习:先在通用的大型人脸识别数据集上训练出模型;然后,使用此模型在小型人证比对数据集上微调;
3.与人脸识别面临相同的问题:人脸姿态、光照和表情的变化
论文中并未就此展开讨论,但是数据集 ID-Selfie-B 却涵盖了这些挑战;且他们本就是人脸识别也需处理的问题,所以本蝌蚪认为,这一问题应该放在「基础模型」部分,也就是人脸识别部分做处理;
三、贡献
针对人证比对问题:
四、结论
- 由于应用场景不同,所以面临的难题也不同,这使得通用人脸验证方法在人证比对问题上效果很差,而本文设计的 DocFace 效果非常好;
- 只要训练集扩大,算法的性能就会稳定提升;
五、基本流程/解决方案 —— DocFace
前导知识:人脸识别,CNN,深度学习基本知识;
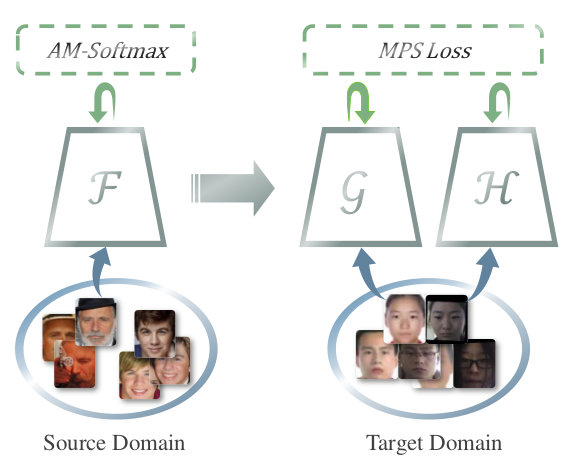
第一步 Train on source domain:在源数据集上训练出基础模型
MA-Celeb-1M:Face-ResNet1 + AM-Softmax 损失函数;
第二步 Train on target domain:在目标数据集上训练出最终模型
ID-Selfie-A:基础模型 + MPS 损失函数 + 兄弟网络 (迁移学习/微调);
将数据集中的证件照和自拍照分别送入两个网络;
六、实验
数据准备:使用 MTCNN 检测并裁剪出人脸,并利用关键点对齐,resize 到 96 * 112;
(一)数据集
1. ID-Selfie-A
自建数据集,由证件照及对应的自拍照组成,共 10,000 对;能够进行人脸对齐的共 9,915 对,也就是 19,830 张图像;
2. ID-Selfie-B
自建数据集,由证件照及对应的自拍照组成,共 547 组,10,844 张;进行人脸对齐及清洗后,还有 537 组,10,806 张;
相比 ID-Selfie-A,本数据集中的自拍照,无约束程度更强;
(二)实验结果
- 基础模型
速度:1080Ti GPU,11G 显存,前向传播一张图 3ms;
准确度:FAR 为 0.1% 的条件下,基础模型在 LFW 上是 99.67%,BLUFR 上是 99.6%;
1. 探索实验
探究 DocFace 有效性时,为什么没有设计「融合数据集」比对实验,也就是验证是迁移学习有效,还是数据融合有效
结论一:
1.大数据集比小数据集训练出的模型效果更好,小数据集非常容易过拟合;
2.针对 ID-Selfie-A 数据,在 MA-Celeb-1M 训练结果上微调后比直接用MA-Celeb-1M 上的训练结果有较大提高;
3.DocFace 的策略非常有效,尤其以 MPS 损失函数 贡献最大,孪生网络 对结果有非常微小的提升;
使用数据集:MA-Celeb-1M,ID-Selfie-A
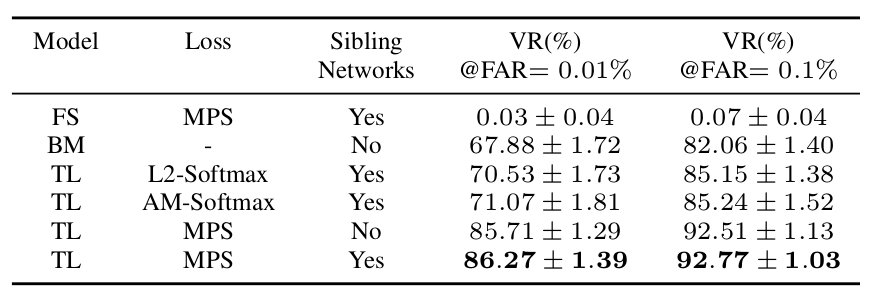
FS:从零开始训练 BM:基础模型,未经过微调的 TL:经过微调的模型 VR:验证准确率 -:没有训练,这一项就为空
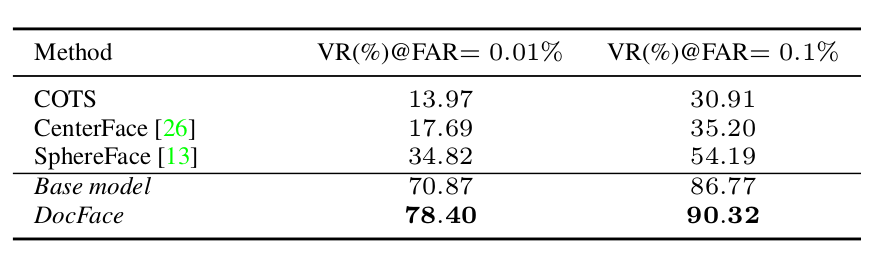
2. 对比实验
结论二:
DocFace 在 人证比对 问题上,效果远胜于 SphereFace2、CenterFace3 和 COTS;
上述结论,文中并未给出,不知是出于学术严谨,还是实验只关注 DocFace 够不够好
准确度排序:DocFace > SphereFace > CenterFace > COTS;
使用数据集:MA-Celeb-1M,ID-Selfie-A,LFW 待补充
LFW:仅用于测试,未参与训练;

为什么 DocFace 没有在 LFW 上进行测试
结论三:
1.数据集 ID-Selfie-B 比 ID-Selfie-A 场景更复杂,无约束程度更高;
2.DocFace 不仅验证准确度最优,且泛化能力也远胜于 SphereFace2、CenterFace3 和 COTS;
上述结论,文中并未给出,不知是出于学术严谨,还是实验只关注 DocFace 够不够好
泛化能力排序:DocFace > SphereFace > COTS > CenterFace;
使用数据集:ID-Selfie-B
为什么 base model 不在 ID-Selfie-A 上做测试呢 base model 带到底是个啥东西,咋训练的
3. 关于数据集大小对准确度影响的实验
结论四:
随着数据量的增大,模型效果越来越好;
使用数据集:ID-Selfie-A
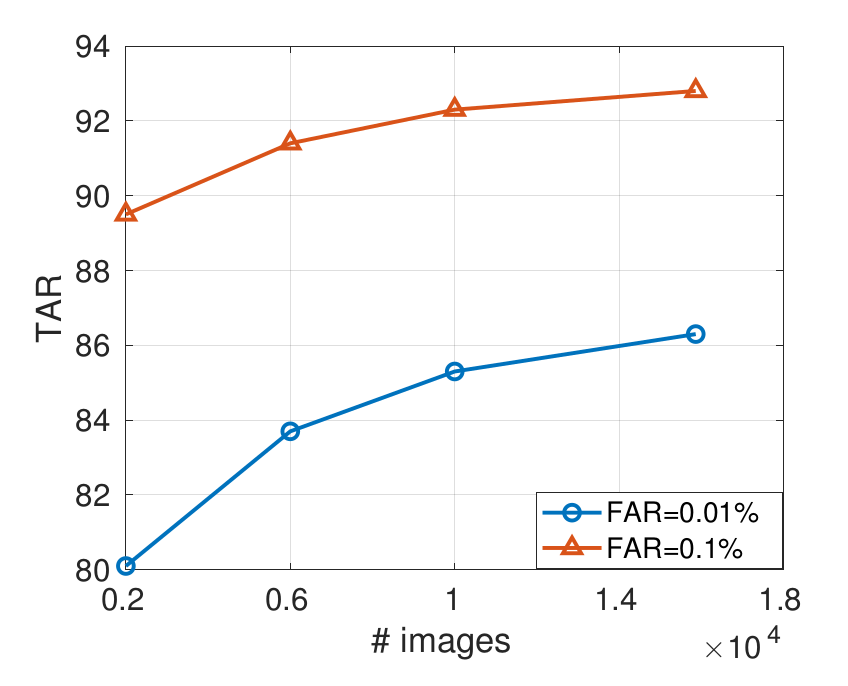
横左标:图像数量 纵坐标:准确度
七、细节
(一)概念
COTS
Commercial-Off-The-Shelf:目前商用的人脸验证方案;
Max-margin Pairwise Score (MPS) loss
待补充
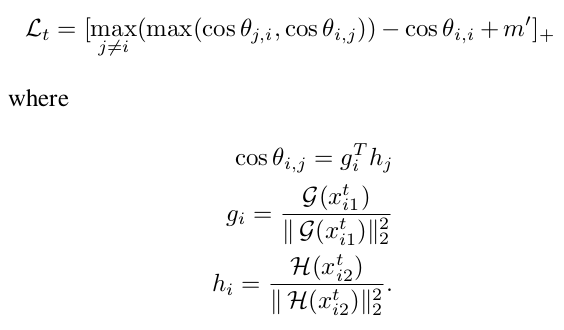
欧式距离 VS 夹角余弦相似度:两个经过 L2 范数归一化之后的矩阵,他们的欧式距离的平方与夹角余弦存在线性关系
\(||\vec x - \vec y||_2^2 = (\vec x - \vec y)^T(\vec x - \vec y)\)
\(= \vec x^T\vec x - 2\vec x^T\vec y + \vec y^T\vec y\)
\(= 2 - 2\vec x^T\vec y\)
\(= 2 - 2cos\theta _{(\vec x, \vec y)}\)
\(G_i\) & \(H_i\):分别是证件照和自拍照的模型输出结果;i 是批次中的第 i 组照片;
两个 max:内层 max 想获取第 i 组数据和第 j 组数据之间证件照与自拍照最大的夹角余弦相似度;外层 max 在循环数据集中所有的组(即训练时的批次);公式中 \(l_t\) 是一对数据计算所的 loss,需对整个批次计算,然后取均值;
兄弟网络 sibling net
网络结构相同,但是独立更新参数的模型的两个网络;
细心的读者会发现此设计和「孪生网络」相似,那么为什么不叫孪生网络呢?
本蝌蚪认为区别在此:「孪生网络」的初衷是为了比较两个输出的相似度,因此将网络复制了一份,很明显,其权值是相同的(即权值共享);而本文的网络设计,初衷是为了针对不同域获取不同的映射方法,以降低其映射到相同域的难度,很明显,两个网络的权重必然不同;所以,「孪生」与「兄弟」最大的区别就在于出发点不同,及随之而来的两个网络权值共享的差异;
本蝌蚪在想,「孪生」或「兄弟」就权值共享问题再做出个变种啥的,该咋命名了哩 ![]()
其实,「sibling net」还有另一个名字,叫「伪孪生网络 pseudo-siamese network」4 ![]()
附录
(一)基本概念
人脸验证/认证
给两张人脸图片,判断是否为同一人;
人证比对
属于人脸验证的范畴,只是其中一张人脸图片来源于证件照;
通用人脸验证方案
使用人脸识别来处理人脸验证问题:对于输入图像,使用人脸识别模型,截取中间层的输出(即该层对应的 feature map)作为图像的特征;然后使用相似度计算算法度量两张图片的相似性;
(二)损失函数
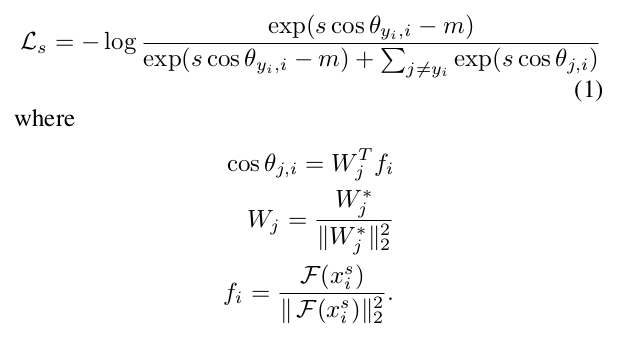
(三)数据集
1. MS-Celeb-1M8
人脸识别数据集,数据集中存在错误标注;
| 数据 | 训练集(张) | 测试集(张) |
|---|---|---|
| 原数据集 | 8,456,240 | 99,892 |
| 清洗后 | 5,041,527 | 98,687 |
下载地址
-
A. Hasnat, J. Bohné, J. Milgram, S. Gentric, and L. Chen. Deepvisage: Making face recognition simple yet with powerful generalization skills. arXiv:1703.08388, 2017. ↩
-
W. Liu, Y. Wen, Z. Yu, M. Li, B. Raj, and L. Song. Sphereface: Deep hypersphere embedding for face recognition. In CVPR, 2017. ↩ ↩2
-
Y. Wen, K. Zhang, Z. Li, and Y. Qiao. A discriminative feature learning approach for deep face recognition. In ECCV, 2016. ↩ ↩2
-
mountain blue. Siamese network 孪生神经网络–一个简单神奇的结构. https://zhuanlan.zhihu.com/p/35040994 ↩
-
F. Wang, W. Liu, H. Liu, and J. Cheng. Additive margin softmax for face verification. arXiv:1801.05599, 2018. ↩
-
J. Deng, J. Guo, and S. Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. arXiv:1801.07698, 2018. ↩
-
H. Wang, Y. Wang, Z. Zhou, X. Ji, Z. Li, D. Gong, J. Zhou, and W. Liu. Cosface: Large margin cosine loss for deep face recognition. arXiv:1801.09414, 2018. ↩
-
Y. Guo, L. Zhang, Y. Hu, X. He, and J. Gao. Ms-celeb-1m: A dataset and benchmark for large scale face recognition. In ECCV, 2016. ↩